X
Earn SEUs Automatically
Add SEUs to your Scrum Alliance account by simply reading articles and viewing videos
As you explore the Resource Library, you’ll see a grey badge indicating eligible content for earning SEUs:

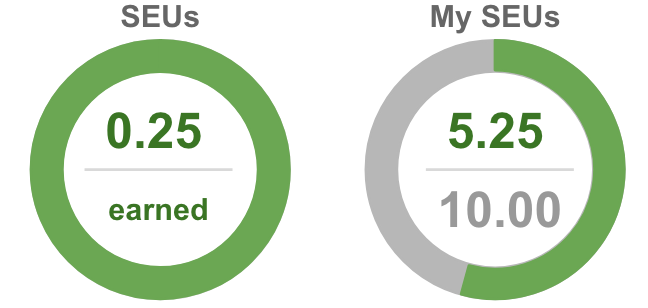
Once you complete the learning, the badge turns green and the SEU credit is added to your personalized My SEUs counter:
💡 Tip: The easiest way to earn your SEUs is to ensure you are logged in as you explore content in the Resource Library.
Discover a Better Way to Work
A curated collection of resources for those who want to become more agile.
Stay connected with the latest resources in your inbox
NEW! Earn SEUs
Find out how to achieve greater results using agile frameworks like Scrum.
Most recent
Top Picks
More Resources
Stay Connected
Get the latest resources from Scrum Alliance delivered straight to your inbox
Subscribe